TritonServer的常用功能介绍
一、概述
Triton 推理服务器可助力团队在任意基于 GPU 或 CPU 的基础设施上部署、运行和扩展任意框架中经过训练的 AI 模型,进而精简 AI 推理。同时,AI 研究人员和数据科学家可在不影响生产部署的情况下,针对其项目自由选择合适的框架。它还帮助开发者跨云、本地、边缘和嵌入式设备提供高性能推理。
- 支持多个框架。Triton 推理服务器支持所有主流框架,例如 TensorFlow、NVIDIA® TensorRT™、PyTorch、MXNet、Python、ONNX、RAPIDS™ FIL(用于 XGBoost、scikit-learn 等)、OpenVINO、自定义 C++ 等
- 高性能推理。Triton 支持所有基于 NVIDIA GPU、x86 和 ARM® CPU 的推理。它具有动态批处理、并发执行、最优模型配置、模型集成和串流输入等功能,可更大限度地提高吞吐量和利用率。Triton 可在单个 GPU 或 CPU 上并行指定相同或不同框架下的多个模型。在多 GPU 服务器中,Triton 会自动为基于每个 GPU 的每个模型创建一个实例,以提高利用率;它还可在严格的延迟限制条件下优化实时推理服务,通过支持批量推理来更大限度地提高 GPU 和 CPU 利用率,并内置对音频和视频流输入的支持。对于需要使用多个模型来执行端到端推理(例如对话式 AI)的用例,Triton 支持模型集成;模型可在生产环境中实时更新,无需重启 Triton 或应用。Triton 支持对单个 GPU 显存无法容纳的超大模型进行多 GPU 以及多节点推理。
- 专为 DevOps 和 MLOps 设计。Triton 与 Kubernetes 集成,可用于编排和扩展,导出 Prometheus 指标进行监控,支持实时模型更新,并可用于所有主流的公有云 AI 和 Kubernetes 平台。它还与许多 MLOPS 软件解决方案集成。
二、快速部署
准备tritonserver的镜像
拉取官方镜像:
docker pull nvcr.io/nvidia/tritonserver:21.10-py3
在算法服务器上已经有基础的tritonserver镜像,如果使用transformers需要自行安装模块。
nvcr.io/nvidia/tritonserver:21.10-py3-base
由于采用ONNX格式的模型文件,推理框架与训练框架无关。统一采用onnxruntime推理框架。下面以发文通用情感词为例,需要修改两个配置文件。
完成配置文件
将onnx格式模型放到配置文件emotion_content_model/1/,数字1表示当前版本,模型的配置文件emotion_content_model/config.pbtxt,主要配置实例数和推理资源。
platform: "onnxruntime_onnx"
max_batch_size: 1024
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "token_type_ids"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
output [
{
name: "linear_75.tmp_1"
data_type: TYPE_FP32
dims: [ 2 ]
}
]
instance_group [
{
count: 1
kind: KIND_GPU
}
]
第二个配置文件emotion_content/config.pbtxt 。这个文件主要是配置端到端的模型,定义tokenizer模型->模型推理->proprecess后处理模型,3个模型的数据流。配置文件通常只需要改动模型名称,model_name: "emotion_content_model",其余保持不变。
output_map {
key: "OUTPUT_1"
value: "tokenizer_token_type_ids"
}
},
{
model_name: "emotion_content_model"
model_version: 1
input_map {
key: "input_ids"
value: "tokenizer_input_ids"
}
input_map {
key: "token_type_ids"
value: "tokenizer_token_type_ids"
}
完整的配置目录如下:
├── emotion_content
│ ├── 1
│ └── config.pbtxt
├── emotion_content_model
│ ├── 1
│ │ └── model.onnx
│ └── config.pbtxt
├── seqcls_postprocess
│ ├── 1
│ │ ├── model.py
│ └── config.pbtxt
└── tokenizer
├── 1
│ ├── model.py
└── config.pbtxt
如果采用不同的模型,对应的分词器不同,需要注意tokenizer/1/model.py的python后端模型。
启动模型服务
启动tritonserver服务,需要制定当前的模型仓库。
docker run --rm --gpus all -dit -p 9000:8000 \
-p 9001:8001 \
-p 9002:8002 \
--shm-size="10g" \
--name emotion_words_hello \
-v /mnt/hdd1/model_repository:/models \
nvcr.io/nvidia/tritonserver:21.10-py3-base tritonserver --model-repository=/models
服务会默认启动3个端口,容器内容端口默认启动8000,8001,8002 分别是http调用、grpc调用和metrics接口。
检查模型是否部署成功:
curl -v 172.16.7.108:8000/v2/health/ready
* Trying 172.16.7.108:8000...
* Connected to 172.16.7.108 (172.16.7.108) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: 172.16.7.108:8000
> User-Agent: curl/7.82.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host 172.16.7.108 left intact
客户端调用
通过HTTP调用
POST 172.16.7.108:9000/v2/models/emotion_content/infer
{
"parameters" : { "sequence_id" : 9 },
"inputs" : [
{
"name" : "INPUT",
"shape" : [2, 1 ],
"datatype" : "BYTES",
"data" : ["黑苦荞茶的功效与作用及食用方法","阿迪达斯"]
}
]
}
通过GRPC客户端调用
常用API汇总
模型的状态是部署成功
curl -v 172.16.7.108:8000/v2/health/ready
获取模型的配置文件
curl -v 172.16.7.108:8000/v2/models/<model name>/config
postman测试模型推理
# POST ip:post/v2/models/<model name>/infer
POST 172.16.7.108:9000/v2/models/emotion_content/infer
{
"parameters" : { "sequence_id" : 9 },
"inputs" : [
{
"name" : "INPUT",
"shape" : [2, 1 ],
"datatype" : "BYTES",
"data" : ["黑苦荞茶的功效与作用及食用方法","阿迪达斯"]
}
]
}
获取模型的推理metrics,详细输出见文档最后
curl ip:port/metrics
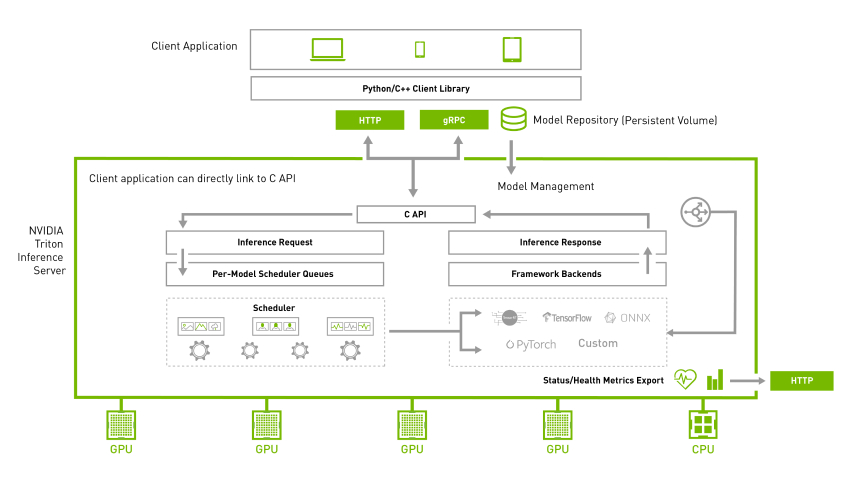
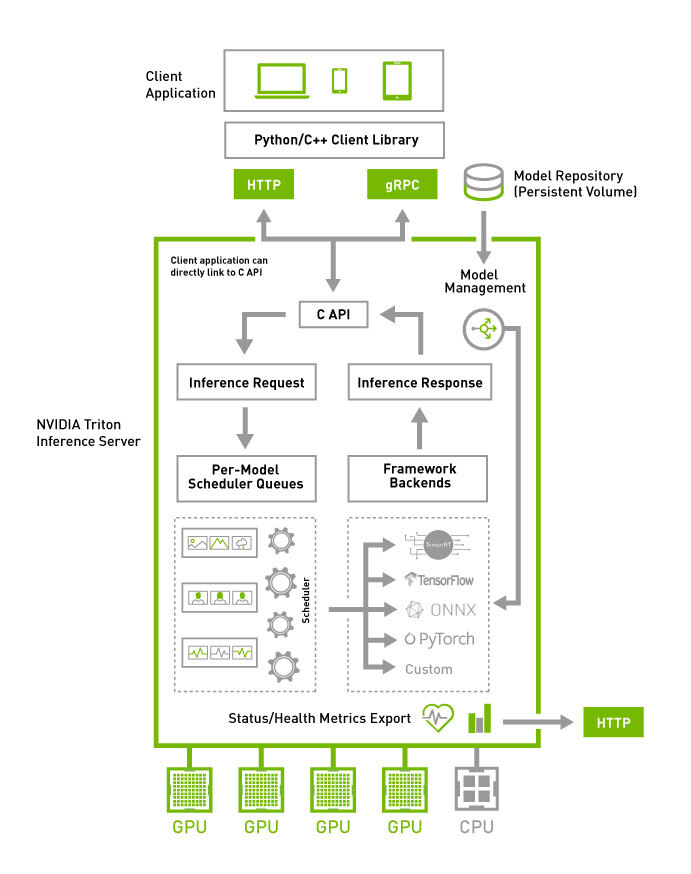
三、架构
四、支持后端
NVIDIA Triton推理服务器为在CPU和GPU上部署深度学习模型提供了完整的解决方案,支持各种框架和模型执行后端,包括PyTorch、TensorFlow、ONNX、TensorRT等。从21.06.1版本开始,为了补充NVIDIA Triton推理服务器现有的深度学习功能,新的森林推理库(FIL)后端支持树模型,如XGBoost、LightGBM、Scikit-LearnRandom Forest、RAPIDS cuML随机森林和Treelite支持的任何其他模型。
TensorRT模型
platform: "tensorrt_plan"
max_batch_size: 8
input [
{
name: "input0"
data_type: TYPE_FP32
dims: [ 16 ]
},
{
name: "input1"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
output [
{
name: "output0"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
ONNX模型
platform: "onnxruntime_onnx"
max_batch_size: 1024
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "token_type_ids"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
output [
{
name: "linear_75.tmp_1"
data_type: TYPE_FP32
dims: [ 2 ]
}
]
TorchScript模型
name: "tokenizer"
backend: "python"
max_batch_size: 1024
input [
{
name: "INPUT_0"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "OUTPUT_1"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
TensorFlow模型
OpenVINO模型
Python模型
name: "tokenizer"
backend: "python"
max_batch_size: 1024
input [
{
name: "INPUT_0"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "OUTPUT_1"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
DALI模型
集成树模型
XGBoost、Scikit-Learn RandomForest、LightGBM等模型部署,下面是部署案例
Real-time Serving for XGBoost, Scikit-Learn RandomForest, LightGBM, and More | NVIDIA Technical Blog
五、模型配置
配置获取
最小模型配置必须指定平台和/或后端属性、max_batch_size属性以及模型的输入和输出张量。模型部署以后可以通过HTTP接口访问模型的配置。
$ curl localhost:8000/v2/models/<model name>/config
CPU模型实例
instance_group [
{
count: 2
kind: KIND_CPU
}
]
版本策略
每个模型可以有一个或多个版本。模型配置的ModelVersionPolicy属性用于设置以下策略之一。
- 全部:模型存储库中可用的模型的所有版本都可以进行推断。version_policy: { all: {}}
- 最新:存储库中只有最新的“n”版本的模型可用于推断。该模型的最新版本是数字最大的版本号。version_policy: { latest: { num_versions: 2}}
- 具体:只有特定列出的模型版本可供推断。version_policy: { specific: { versions: [1,3]}}
实例组
默认情况下,为系统中可用的每个GPU创建模型的单个执行实例。实例组设置可用于在每个GPU或仅在某些GPU上放置一个模型的多个执行实例。例如,以下配置将在每个系统GPU上放置两个模型执行实例。
instance_group [
{
count: 2
kind: KIND_GPU
}
]
以下配置将在GPU 0上放置一个执行实例,在GPU 1和2上放置两个执行实例。
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0 ]
},
{
count: 2
kind: KIND_GPU
gpus: [ 1, 2 ]
}
]
六、模型测试与分析
triton server部署的模型,官方提供的测试工具perf_analyzer,工具已经配置好在算法服务器容器,每次启动容器,即可测试模型推理性能。
docker run --gpus all \
--rm -it --net host nvcr.io/nvidia/tritonserver:23.02-py3-sdk
测试命令:
# -m 模型名称 -x 模型版本 -u 模型http地址 -b batch size -p 测试窗口时间
# 更多参数自行参考help文档
perf_analyzer -m emotion_content \
-x 1 \
-u 172.16.7.108:8000 \
-b 16 \
-p 5000 \
--percentile 95 \
--concurrency-range 1:8
测试发文通用情感词案例:
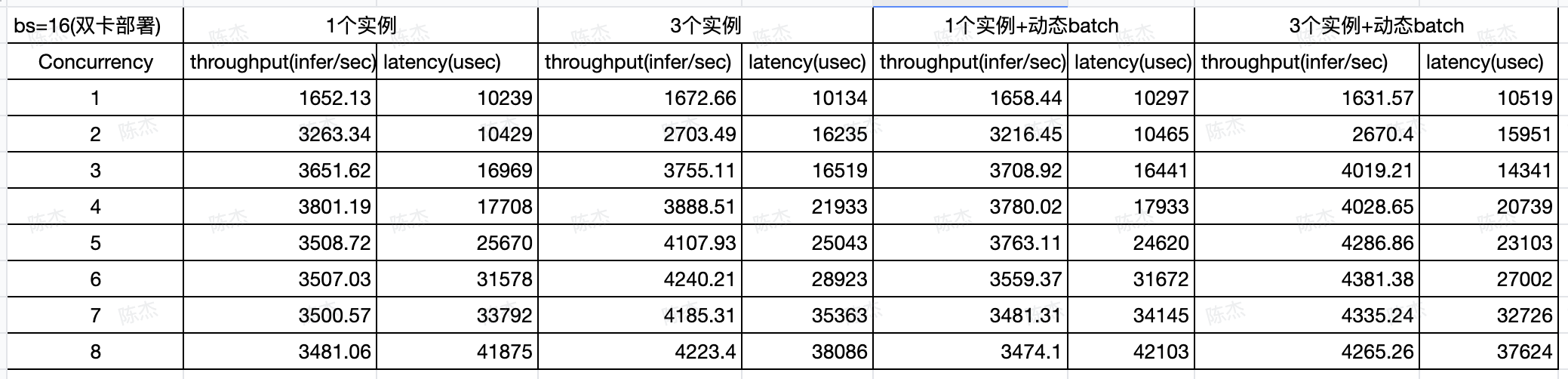
七、优化
模型实例
通过增加模型实例来提升模型的吞吐量
instance_group [
{
count: 2
kind: KIND_GPU
}
]
具体提升效果需要通过测试工具
动态批处理
动态批处理机将单个推理请求组合成一个更大的批次,通常比独立执行单个请求更高效地执行。要启用动态batcher停止Triton,请在模型配置文件的末尾添加以下行,然后重新启动Triton
dynamic_batching { }
ONNX与TensorRT优化
一个特别强大的优化是将TensorRT与ONNX模型结合使用。作为应用于ONNX模型的TensorRT优化示例,作为基线,我们使用perf_analyzer使用不启用任何性能优化的基本模型配置来确定模型的性能
optimization { execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" }
parameters { key: "max_workspace_size_bytes" value: "1073741824" }
}]
}}
TensorRT优化提供了2倍的吞吐量改进,同时将延迟减少了一半。TensorRT提供的好处将因型号而异,但一般来说,它可以提供显著的性能改进。
更多优化配置参考:
Optimization — NVIDIA Triton Inference Server
八、运行指标metrics
Triton提供Prometheus 指标,监控GPU和请求统计数据。默认情况下,这些指标可在http://localhost:8002/metrics上获得。这些指标仅通过访问端点可用,不会推送或发布到任何远程服务器。公制格式是纯文本,因此您可以直接查看它们,例如:
GET http://172.18.193.164:8002/metrics
# HELP nv_inference_request_success Number of successful inference requests, all batch sizes
# TYPE nv_inference_request_success counter
nv_inference_request_success{model="seqcls_yingxiao",version="1"} 619087.000000
nv_inference_request_success{model="tokenizer",version="1"} 619087.000000
nv_inference_request_success{model="seqcls_postprocess_yingxiao",version="1"} 619087.000000
nv_inference_request_success{model="seqcls_model_yingxiao",version="1"} 619087.000000
# HELP nv_inference_request_failure Number of failed inference requests, all batch sizes
# TYPE nv_inference_request_failure counter
nv_inference_request_failure{model="seqcls_yingxiao",version="1"} 1.000000
nv_inference_request_failure{model="tokenizer",version="1"} 0.000000
nv_inference_request_failure{model="seqcls_postprocess_yingxiao",version="1"} 0.000000
nv_inference_request_failure{model="seqcls_model_yingxiao",version="1"} 0.000000
# HELP nv_inference_count Number of inferences performed
......
包括推理请求指标,GPU指标,CPU指标,响应缓存指标等,具体含义参考