kafka消费的重平衡策略
算法推理服务的日处理能力当前已经达到千万级别,我们的算法系统采用Kafka流式消费。系统经常面临的一个重要问题就是消息积压,这时候就需要增加推理算力。如何动态的增减推理实例数,以保障消息不丢失,同时也不需要修改服务代码。本文做了一个小实验,验证多个消费者同时消费同一个topic,消息是否会丢失,或者存在重复消费的情况。
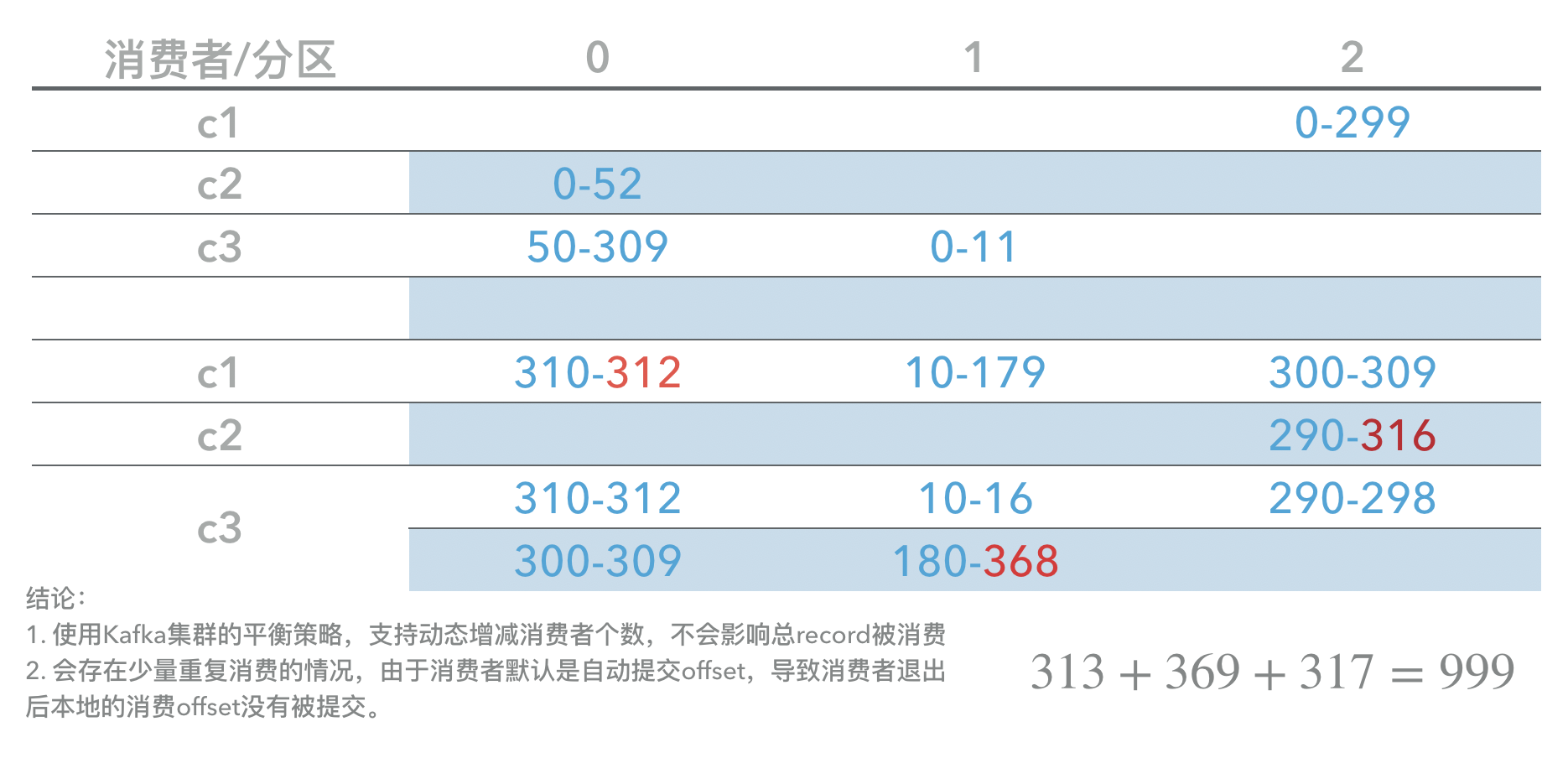
创建消费的topic 3个分区,意味着同一个消费者组最多3个消费者可以消费。消费者分别用3个消费脚本,每个消费者单进程消费。消费者不绑定分区,消费者实例采用默认的参数。具体参数可以参考kafka-python。
统计了消费结果如下:

上表中为offset结果,可以看到存在部分重复消费的情况,这是因为终端机消费者进程时,还未提交到集群,以至于偏移量offset没有更新。由于配置参数Kafka消费者每次最多poll10条数据,可以看到重复消费的情况并不严重。
topic中放了999条record被全部消费,说明随机终止和重启消费者进程,并不会丢失record,说明Kafka集群的重平衡机制是可以信任的。其实Kafka的重平衡机制是由消费者参数`api_version``来指定的。
api_version (tuple) –
Specify which Kafka API version to use. If set to None, the client will attempt to infer the broker version by probing various APIs. Different versions enable different functionality.
Examples
(0, 9)** enables full group coordination features with automatic
partition assignment and rebalancing**
结论
通过实验随机中断和重复消费者,不影响Kafka的消费,同一个消费者组的消费者数变化,会触发集群的重平衡机制。重新分配消费者对应分区。